
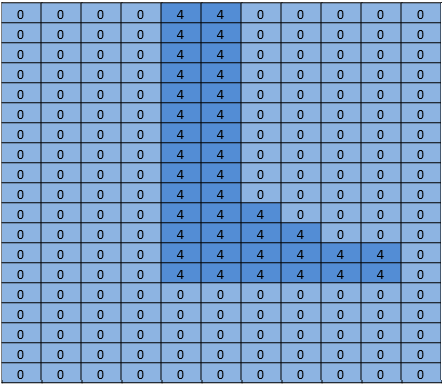
A segmentation network segments the image's pixels into areas that are occupied by the objects on our list. It answers the question by returning an array with an entry corresponding to each pixel in the image. Each entry has a value of zero if it is a background pixel, or an value of one to n for the n different objects it is capable of recognizing. This made up example could be the guy's foot:
This project is part of a larger project attempting to drive an RC car with a computer. The idea is to use the neural network to find the pose (global 3d position and orientation) of the car to feed to the navigation routines. The camera is fixed and the lawn is basically flat. I can use a bit of trig to derive the 3d position if the neural net can come up with the screen pixels and the orientation. The cat's role in all of this is "possible destination".
I started off thinking primarily about the car since I had the most uncertainty about how that would work out, assuming that recognizing a cat with a pre-trained network would be trivial. After a bunch of work that I won't detail in this note, I decided that it is possible to determine the orientation of the car with a fairly high degree of confidence. Here's a training shot at an angle of 292.5 degrees:

Most of that work was done with a classification network, Caffe's bvlc_reference_caffenet model. So I set out to find a segmentation network to give me the screen position of the car.
The first network I considered is Faster R-CNN [1]. It returns bounding boxes for objects in the image rather than pixels. But running the network on the Jetson was too slow for this application. The bounding box idea was very appealing though, so I also looked at driving oriented network [2]. It was too slow as well. FCN [3] turned out to be the fastest segmentation network I tried. "FCN" stands for "Fully Convolutional Network". The switch to only convolutional layers lead to a substantial speed up, classifying my images in about 1/3 of a second on the Jetson. FCN includes a nice set of Python scripts for training and easy deployment. The Python scripts resize the network to accommodate any inbound image size, simplifying the main image pipeline. I had a winner!
The FCN github release has several variants. I tried voc-fcn32s first. It worked great. Voc-fcn32s has been pre-trained on the standard 20 voc classes. Since it's so easy, I next gave pascalcontext-fcn32s a try. It has been trained on 59 classes, including grass and trees, so I thought that it must be better. Turns out that this is not necessarily good - there were many more pixels set in the output images and the segmentation of cats and people overlaying the grass and shrubs was not as precise. The segmentation from siftflow was even more complicated so I quickly dropped back to the voc variants.
Sticking with voc networks still means there are three to consider: voc-fcn32s, voc-fcn16s, and voc-fcn8s. These differ by the "stride" of the output segmentation. Stride 32 is the underlying stride of the network: a 640x360 image is reduced to a 20x11 network by the time the convolutional layers complete. This coarse segmentation is then "deconvolved" back to 640x360, as described in [3]. Stride 16 and stride 8 are accomplished by adding more logic to net to make a better segmentation. I haven't tried either - the 32s segmentation is the first one I tried and I've stuck with it because the segmentation looks fine for this project and the training as described looks more complex for the other two networks.


The first thing I noticed when I got the system up and running is that only about 30% of the cats were recognized by the network. I found two reasons for that. The first is that cats often visit at night so the camera sees them in infrared light. That should be easy to fix - just add a few segmented infrared cat images to the training. The second issue I found after a review of a few hundred pictures of cats from the training set is that many pictures are of the "look at my cute kitty" variety. They are frontal images of the cat at the cat's eye level. Or the cat is lying on its back or lying on the owner's lap. They don't look like the cats slinking around in my yard. Again, should be easy to fix with some segmented daytime images.
How to segment an item in a training image? My approach is to subtract a background image then doctor up the foreground pixels to indicate what the thing is. This works pretty well in practice because I usually have an image in my camera archive that was taken within a few seconds of the image to be segmented. But there are artifacts to clean up and the segmentation often needs refining so I ended up writing a rough-and-ready image segment editing utility, src/extract_fg.cpp. See the note at the top of the source file for usage. It's a bit clunky and has little error checking and needs some clean-up but it works well enough for the job.
Now that we have some images to train with let's see how to do it. I cloned voc-fcn32s into the directory rgb_voc_fcn32s. All of the file names will refer to that directory for the rest of this tutorial.
$ cp -r voc-fcn32s rgb_voc_fcn32s
The code is in my github, including a sample training file in data/rgb_voc. The main changes include these:
$ head data/rgb_voc/train.txt
/caffe/drive_rc/images/negs/MDAlarm_20160620-083644.jpg /caffe/drive_rc/images/empty_seg.png
/caffe/drive_rc/images/yardp.fg/0128.jpg /caffe/drive_rc/images/yardp.seg/0128.png
/caffe/drive_rc/images/negs/MDAlarm_20160619-174354.jpg /caffe/drive_rc/images/empty_seg.png
/caffe/drive_rc/images/yardp.fg/0025.jpg /caffe/drive_rc/images/yardp.seg/0025.png
/caffe/drive_rc/images/yardp.fg/0074.jpg /caffe/drive_rc/images/yardp.seg/0074.png
/caffe/drive_rc/images/yard.fg/0048.jpg /caffe/drive_rc/images/yard.seg/0048.png
/caffe/drive_rc/images/yard.fg/0226.jpg /caffe/drive_rc/images/yard.seg/0226.png
I replaced voc_layers.py with rgb_voc_layers.py which understands the new scheme:
--- voc_layers.py 2016-05-20 10:04:35.426326765 -0700
+++ rgb_voc_layers.py 2016-05-31 08:59:29.680669202 -0700
...
- # load indices for images and labels
- split_f = '{}/ImageSets/Segmentation/{}.txt'.format(self.voc_dir,
- self.split)
- self.indices = open(split_f, 'r').read().splitlines()
+ # load lines for images and labels
+ self.lines = open(self.input_file, 'r').read().splitlines()
And changed train.prototxt to use my rgb_voc_layers code. Note that the arguments are different as well.
--- voc-fcn32s/train.prototxt 2016-05-03 09:32:05.276438269 -0700
+++ rgb_voc_fcn32s/train.prototxt 2016-05-27 15:47:36.496258195 -0700
@@ -4,9 +4,9 @@
top: "data"
top: "label"
python_param {
- module: "layers"
- layer: "SBDDSegDataLayer"
- param_str: "{\'sbdd_dir\': \'../../data/sbdd/dataset\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
+ module: "rgb_voc_layers"
+ layer: "rgbDataLayer"
+ param_str: "{\'input_file\': \'data/rgb_voc/train.txt\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 1
Almost the same change to val.prototxt:
--- voc-fcn32s/val.prototxt 2016-05-03 09:32:05.276438269 -0700
+++ rgb_voc_fcn32s/val.prototxt 2016-05-27 15:47:44.092258203 -0700
@@ -4,9 +4,9 @@
top: "data"
top: "label"
python_param {
- module: "layers"
- layer: "VOCSegDataLayer"
- param_str: "{\'voc_dir\': \'../../data/pascal/VOC2011\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
+ module: "rgb_voc_layers"
+ layer: "rgbDataLayer"
+ param_str: "{\'input_file\': \'data/rgb_voc/test.txt\', \'seed\': 1337, \'split\': \'seg11valid\', \'mean\': (104.00699, 116.66877, 122.67892)}"
$ python rgb_voc_fcn32s/solve.py
It overrides some of the normal Caffe machinery. In particular, the number of iterations is set at the
bottom of the file. In this particular set-up, an iteration is a single image because the network is
resized for each image and the images are pushed through one at a time.
One of great things about working for Nvidia is that really great hardware is available. I have a Titan board in desktop and my management was OK with letting me use it for something as dubious as this project. My last training run was 4000 iterations. It took just over two hours on the Titan.
[2] An Empirical Evaluation of Deep Learning on Highway Driving Brody Huval, Tao Wang, Sameep Tandon, Jeff Kiske, Will Song, Joel Pazhayampallil, Mykhaylo Andriluka, Pranav Rajpurkar, Toki Migimatsu, Royce Cheng-Yue, Fernando Mujica, Adam Coates, Andrew Y. Ng arXiv:1504.01716v3, github.com/brodyh/caffe.git
[3] Fully Convolutional Networks for Semantic Segmentation Jonathan Long, Evan Shelhamer, Trevor Darrell arXiv:1411.4038v2, github.com/shelhamer/fcn.berkeleyvision.org.git
Contact me at r.bond@frontier.com for questions or comments.